
سایت بدون -شبکههای عصبی با الهام از زیستشناسی، گامهای بلندی را در جهت تقویت تواناییهای انسان برمیدارند. آیا میتوان با کاهش قابلیت پیشبینی، هوش مصنوعی را به هوش انسانی نزدیک کرد؟
زومیت نوشت: کنت استنلی، دانشمند علوم کامپیوتر دانشگاه فلوریدای مرکزی، در سال ۲۰۰۷ روی سایتی بهنام Picbreeder کار میکرد که همراهبا دانشجویان خود برای پژوهشی موردی طراحی کرده بود؛ اما دیدن موجودی فرازمینی که به خودرویی مسابقهای تبدیل شده بود، مسیر زندگی استنلی را تغییر داد.
کاربران در سایت Picbreeder، آرایهای از ۱۵ تصویر مشابه را میبینند که از شکلهای هندسی و الگوهای پیچان تشکیل شدهاند. تمام تصاویر نمونههای متغیری از یک زمینه هستند. گاهی اوقات برخی شکلها مشابه شکلهای واقعی مثل پروانه یا چهره بهنظر میرسند. استنلی از کاربرها خواست روی اشکالی که برایشان جذاب است، کلیک کنند. پس از این کار، مجموعهای جدید از تصاویر براساس انتخاب آنها ظاهر شدند. نتیجهی نهایی این بررسی، کاتالوگی از تصاویر خیالی بود.

اصل سنگبنا، روشی برای تزریق خلاقیت به هوش مصنوعی است
استنلی در یکی از زمینههای هوش مصنوعی بهنام تکامل عصبی، پیشتاز است. در این حوزه از روشهای تکامل بیولوژیکی برای طراحی الگوریتمهای هوشمند استفاده میشود. هر کدام از تصاویر سایت Picbreeder خروجی سیستمی محاسباتی مشابهشبکهی عصبی هستند. وقتی تصویری ساخته میشود، شبکهی زیرساخت آن به ۱۵ شکل مختلف تغییر پیدا میکند که نتیجهی هر کدام، تصویری جدید است. هدف استنلی از ساخت Picbreeder تولید تصویر مشخصی نبود. تنها هدف او آموزش نکات جدید دربارهی تکامل و هوش مصنوعی به کاربران سایت بود.
روزی استنلی در میان تصاویر، چهرهای مشابه موجودی فضایی را دید و شروع به تکامل آن کرد. بهطور اتفاقی، چشمهای گرد به سمت پائین حرکت کردند و مشابه چرخهای یک خودرو شدند. استنلی به کار خود ادامه داد و یک خودروی اسپرت زیبا ساخت. این مسئله فکر او را مشغول کرد و از خود پرسید اگر از همان ابتدا بهجای تصویر موجود فضایی، برای ساخت تصویر خودرو تلاش میکرد شاید هرگز به نتیجه میرسید. این اتفاق یک پیام برای او داشت: چرا باید مسائل را بهصورت مستقیم حل کرد. به این ترتیب به سراغ تصاویر جالب دیگری رفت که در Picbreeder ظاهر شده بودند، خطوط آنها را دنبال کرد و متوجه شد تمام تصاویر از شکلی کاملا متفاوت به تکامل رسیدهاند.
درک استنلی به مقدمهی اصل سنگبنا برای طراحی الگوریتمها تبدیل شد. الگوریتمهایی که پتانسیل خلاقیت بینهایت تکامل زیستی را دربرمیگیرند. الگوریتمهای تکاملی، موضوع جدیدی نیستند. همیشه از این الگوریتمها برای حل مسائلی مشخص استفاده شده است. در هر نسل، براساس معیارهایی مشخص، راهحلهایی با بهترین عملکرد انتخاب شدند (برای مثال توانایی کنترل یک ربات دو پایی) و محصولی را تولید کردهاند. الگوریتمهای تکاملی با وجود موفقیت در بعضی نمونهها، از نظر محاسباتی میتوانند بسیار سنگینتر از روشهایی مانندیادگیری عمیق باشند که در سالهای اخیر به محبوبیت زیادی رسیده است.
اصل سنگبنا، فراتر از روشهای سنتی تکاملی عمل میکند. برای مثال بهجای بهینهسازی برای هدفی مشخص، جستجوی خلاق تمام راهحلهای ممکن را در نظر میگیرد. این روش به نتایج بیسابقهای دست یافته است. در سال گذشته، سیستمی براساس اصل سنگبنا موفق شد در دو بازی ویدئویی به مهارت برسد. در این بازیها از روشهای محبوب و رایج یادگیری ماشین استفاده شده بود. از طرفی، شرکت DeepMind که در زمینهی هوش مصنوعی و کاربرد یادگیری عمیق برای حل مسائلی مثل بازی Go مهارت دارد، موفق به ترکیب یادگیری عمیق با تکامل مجموعهای از راهحلهای متنوع شد.
از تکامل زیستی میتوان برای توسعهی هوش مصنوعی نزدیک به انسان استفاده کرد
پتانسیل اصل سنگبنا در مقایسه با تکامل زیستی آشکار میشود. در طبیعت، درخت زندگی هیچ هدف جامعی ندارد و قابلیتهایی که برای یک عمل یا فرایند خاص در نظر گرفته میشوند ممکن است در فرایندی کاملا متفاوت هم نقش داشته باشند. برای مثال، پرها بهعنوان عایق به تکامل رسیدند اما بعدها به وسیلهای برای پرواز هم تبدیل شدند.
تکامل بیولوژیکی، تنها سیستم موجود برای تولید هوش انسانی و رویای نهایی بسیاری از پژوهشگران هوش مصنوعی است. استنلی و دیگر پژوهشگران این حوزه، معتقدند براساس سوابق زیستی برای ساختالگوریتمی که بتواند دنیای اجتماعی و فیزیکی را به آسانی کنترل کند، باید از طبیعت تقلید کرد. بهجای کدنویسی سخت (روشی برای توسعهی نرمافزار) قوانین استنتاج یا کامپیوترهایی که براساس معیارهای عملکردی قادر به درجهبندی باشند، باید از مجموعهی راهحلها استفاده کرد. باید ویژگیهایی مثل نوآوری و جذابیت را بهجای تواناییهای راه رفتن یا صحبت کردن در اولویت قرار داد. درنتیجه میتوان به مسیری غیرمستقیم و مجموعهای از سنگبناها دست یافت و از آنها برای بهبود راه رفتن یا صحبت هم استفاده کرد که شاید از روشهای مستقیم امکانپذیر نباشند.

چهرهی موجودی فضایی که در Picbreeder ساخته شده است (سمت چپ) پس از تکامل، به خودروی مسابقهای سمت راست تبدیل شد
جدید، جذاب، متنوع
استنلی پس از تجربهی Picbreeder برای اثبات تکامل عصبی، در سطح گستردهای تلاش کرد. او میگوید: طراحی الگوریتمی که نتوان میزان خلاقیت آن را پیشبینی کرد، از دیدگاه پژوهشی جذاب است اما فروش تجاری آن کار دشواری است.
استنلی امیدوار است با استفاده از ایدههای تکامل عصبی، الگوریتمها نهتنها بتوانند انواع نتایج را تولید کنند بلکه قادر به حل مسائل هم باشند. استنلی میخواهد ثابت کند گاهی نادیده گرفتن هدف بیشتر از دنبال کردن آن، ما را به هدف نزدیک میکند. او این کار را از طریق روشی بهنام جستجوی نوآورانه (novelty search) انجام میدهد.
در جستجوی نوآورانه، سیستمی با شبکهای عصبی راهاندازی میشود که ترکیبی از عناصر محاسباتی کوچک بهنام نورونهای متصل در لایهها است. خروجی یک لایه از نورونها از طریق اتصالهایی با وزنهای مختلف به لایهی بعدی منتقل میشود. در نمونهای ساده، دادههای ورودی از جمله تصاویر میتوانند به شبکههای عصبی وارد شوند. با عبور اطلاعات تصویر از لایهای به لایهای دیگر، شبکه به استخراج اطلاعات انتزاعی دربارهی محتوای خود میپردازد. در نهایت، لایهی نهایی به محاسبهی سطح بالاترین اطلاعات میپردازد: برچسبی برای تصویر.
در تکامل نورونی، کار با تخصیص مقادیر تصادفی به وزنهای بین لایهها آغاز میشود. خاصیت تصادفی بهمعنی عملکرد نهچندان خوب شبکه است؛ اما از همین حالت تصادفی میتوان به مجموعهی دیگری از جهشهای تصادفی رسید (شبکههای عصبی با وزنهای متفاوت) و سپس به ارزیابی قابلیت آنها پرداخت. میتوان بهترین جهشها را حفظ کرد، محصولات بیشتری را تولید کرد و سپس همین روند را تکرار کرد. (استراتژیهای تکامل عصبی پیشرفتهتر منجر به تولید جهشهایی براساس تعداد و آرایش نورونها و اتصال آنها میشوند). تکامل نورونی از نوع فراالگوریتم است؛ یعنی الگوریتمی که برای طراحی الگوریتمهای دیگر طراحی شده است و در نهایت هر کدام از الگوریتمها عملکرد خوبی خواهند داشت.

برای کنت استنلی، دانشمند کامپیوتر در آزمایشگاه Uber AI و دانشگاه فلوریدای مرکزی، اصل سنگ بنا بهمعنی نوآوری است
استنلی و دانشجوی او جوئل لمان، برای تست اصل سنگبنا، فرایند انتخاب را تغییر دادند. جستجوی نوآورانه بهجای انتخاب شبکههایی که در وظیفهای خاص عملکرد خوبی دارند، شبکهها را براساس تفاوت آنها با شبکههای مشابه انتخاب میکنند (برای مثال در Picbreeder، جذابیت برای افراد مهم بود. در اینجا جستجوی نوآورانه به نوآوری بهعنوان واسطهای برای انتخاب جذابیت پاداش میدهد).
استنلی و همکارانش در یکی از تستها، رباتهای چرخدار را درون یک هزارتو قرار دارند و به تکامل الگوریتمهای کنترلکنندهی رباتها پرداختند. آنها امیدوار بودند به این ترتیب ربات بتواند راه خروج از هزارتو را پیدا کند. آنها تکامل را ۴۰ مرتبه از ابتدا اجرا کردند. در برنامهای مقایسهای، رباتها براساس میزان نزدیکی با راه خروجی انتخاب میشدند، در این برنامه ربات در چهل مرتبه اجرا تنها سه مرتبه موفق شد راه خروجی را پیدا کند اما در جستجوی نوآورانه که میزان نزدیکی رباتها به راه خروج را نادیده میگیرد، ۳۹ بار موفق شد. دلیل موفقیت این جستوجو، اجتناب رباتها از بنبست بود. بهجای اینکه تصور کنند بنبست همان راه خروج است، به بخشهای ناشناس قدم میگذاشتند، راههای میانبر را پیدا میکردند و بهصورت تصادفی برنده میشدند. جولیان توگلیوس، دانشمند کامپیوتر دانشگاه نیویورک، میگوید: «جستجوی نوآورانه همه چیز را معکوس میکند؛ و در زمانیکه هدفی وجود ندارد میپرسد چه اتفاقی افتاده است؟»
الگوریتمهای تکاملی، مجموعهای از راهحلهای برنده را تولید میکنند
در مرحلهای از تست، تعقیب اهداف میتوانست مانع از رسیدن به آنها شود، بنابراین استنلی بهدنبال راههای هوشمندانهتری برای ترکیب جستجوی نوآورانه و اهداف خاص رفت. او و لمان سیستمی را برای تقلید از نوآوریهای تکاملی طبیعی ساختند. در این روش، الگوریتمها تنها با الگوریتمهای مشابه خود رقابت میکنند. همانطور که کرمها با والها رقابت نمیکنند، سیستم هم دارای موقعیتهای الگوریتمی مجزایی است که هر کدام روشهای خود را تولید میکنند.
الگوریتمهای تکاملی رقابتی محلی، در مواردی مثل پردازش پیکسلها، کنترل بازوی ربات و کمک به تطبیق ربات شش پا پس از حذف یکی از پاها (مانند رفتار حیوانات)، عملکرد بهینهای دارند. یکی از عناصر کلیدی چنین الگوریتمهایی، توسعهی سنگ بناها است. آنها بهجای اولویت بندی مستمر بهترین راهحل، مجموعهی متنوعی از راهحلها را حفظ میکنند که هرکدام میتوانند شامل یک برنده باشند. بهترین راهحل هم از میان همین مجموعهها انتخاب میشود.
تکامل برای برد
برای استنلی که حالا در آزمایشگاه Uber AI فعالیت میکند، اصل سنگبنا نشاندهندهی نوآوری است: اگر با کامپیوتری مدرن به گذشته بازگردید و به مردم بگویید بهجای تولید کامپیوتر روی لپتاپها تمرکز کنند، امروز هیچکدام از آنها را نداشتید. همچنین این اصل توصیف کنندهی تکامل است: انسان از کرمهای مسطح به تکامل رسیدهاند. گرچه این موجودات هوشمند نیستند، دارای تقارن دو طرفه هستند. بهگفتهی استنلی: هنوز مشخص نیست کشف تقارن دو طرفه در گذشته ربطی به هوش داشته است؛ اما امروز این ارتباط آشکار است.
تکامل عصبی در دههی گذشته در مسیری غیرمستقیم حرکت کرده است و به مدت طولانی در سایهی دیگر اشکال AI به حیات خود ادامه داده است. به عقیدهی ریستو میکولاینن، دانشمند کامپیوتر دانشگاه تگزاس (و مشاور سابق دکترای استنلی)، یکی از بزرگترین معایب تکامل عصبی، حجم محاسبات مورد نیاز آن است. در یادگیری ماشین به روش سنتی، شبکهی عصبی از طریق آموزش بهتدریج بهبود پیدا میکند. در تکامل عصبی، وزنها بهصورت تصادفی تغییر میکنند بنابراین احتمال ضعیف شدن عملکرد هم وجود دارد.
یکی از دیگر معایب تکامل عصبی این است که اغلب افراد بهدنبال حل مسئلهای خاص هستند. استراتژی جستجویی که برای بهینهسازی جذابیت مسئله به کار برود میتواند راهحلی خلاقانه را برای یک مسئلهی خاص ارائه کند؛ اما ممکن است مخاطب را قبل از قرار گرفتن در مسیر صحیح، گیج کند.

بازی ویدئویی Montezuma Revenge اولینبار در سال ۱۹۸۴ منتشر شد
بهطور کلی، هیچ راهکار بینقصی وجود ندارد. در پنج سال گذشته، پژوهشهای حوزههای مختلف AI از جمله یادگیری عمیق و یادگیری تقویتی به شکل چشمگیری افزایش پیدا کردهاند. در یادگیری تقویتی، الگوریتم با محیط به تعامل میپردازد و سپس از طریق آزمون و خطا به یادگیری میپردازد و در نهایت رفتار آن نتایج مطلوبی را بهدنبال خواهد داشت. برای مثال رباتی که در دنیای واقعی حرکت میکند یا گیمرها از این الگوریتم استفاده میکنند. شرکت DeepMind از یادگیری تقویتی عمیق برای ساخت برنامهای استفاده کرد که بتواند بهترین بازیکنان بازی Go را شکست دهد. درحالیکه بسیاری تصور میکردند برای رسیدن به این هدف، سالها زمان لازم است.
از طرفی ممکن است یادگیری تقویتی دچار یکنواختی شود. پاداشهای کم یا پراکنده، برای رسیدن الگوریتمها به هدف کافی نیستند. پاداشهای فریبنده (پاداش برای سودهای کوتاهمدتی که مانع از پیشرفت طولانیمدت میشوند) الگوریتمها را به دام بنبست میاندازند؛ بنابراین یادگیری تقویتی میتواند انسانها را به دام بازیهایی از نوعSpace Invaders (مهاجمان فضایی) یا Pong بیندازد. این بازیها با وجود امتیازها و اهداف مشخص، یکنواخت و قابل پیشبینی هستند.
در سال ۲۰۱۸، هوش مصنوعی براساس اصل سنگبنا موفق به حل چالشهای دیرینهای شد. در بازی انتقام مونتزوما (Montezuma’s Revenge)، پاناما جو، کاراکتر اصلی بازی، در دخمهای زیرزمینی برای جمعآوری کلیدها و بازکردن درها از اتاقی به اتاقی دیگر میرود و در این راه باید از دشمنان و موانعی مثل مارها و گودالهای آتش دوری کند. استنلی، لمان، جف کلان، جوست هویزینگا و آدرین اکوفت برای شکست این بازی در آزمایشگاه Uber AI مشغول به کار شدند و سیستمی را طراحی کردند که پاناما جو در آن با جستوجو در اطراف بهصورت تصادفی، کارهای مختلفی را انجام میدهد. با هر بار رسیدن به وضعیتی جدید، آن را بههمراه مجموعهای از عملیات وارد حافظهاش میکند. در صورت یافتن مسیری سریعتر به همان وضعیت، آن مسیر را جایگزین وضعیت قبلی در حافظه میکند. پاناما جو در طول آموزش، بهصورت تکراری یکی از وضعیتهای ذخیرهشده را انتخاب میکند، بهصورت تصادفی به جستوجو میپردازد و وضعیتهای جدید را به حافظهاش اضافه میکند.
در حوزهی هوش مصنوعی هیچ روش بینقصی وجود ندارد و بهتر است روشها را ترکیب کرد
در نهایت یکی از همین وضعیتها به وضعیت برندهی بازی تبدیل میشود. در این مرحله، پاناما جو تمام عملیات لازم برای رسیدن به هدف را ذهن خود دارد. او کار خود را بدون هیچگونه شبکهی عصبی یا یادگیری تقویتی انجام میدهد. هیچ پاداشی برای جمعآوری کلیدها یا نزدیک شدن به پایان دخمه وجود ندارد. فقط فرایند جستجوی تصادفی و راهی هوشمندانه برای جمعآوری و اتصال سنگبناها دیده میشود. این روش نهتنها برای شکست بهترین الگوریتمها بلکه برای شکست رکورد انسانی بازی تنظیم شده است.
روش مشابهی بهنام Go-Explore برای غلبه بر خبرههای انسانی بازی Pitfall به کار رفت. در این بازی پیتفال هری، در جنگلی به جستجوی گنج میپردازد و در این راه باید از کروکودیلها و دامها دوری کند. به جز این روش، هیچکدام از انواع هوش یادگیری ماشین موفق به دریافت امتیاز بالاتر از صفر نشدند.
امروزه حتی DeepMind، بهعنوان منبع یادگیری تقویتی، علاقهی خود به تکامل عصبی را نشان داده است. تیم دیپمایند در ماه ژانویه از نرمافزار AlphaStar رونمایی کردند که میتواند بازیکنهای حرفهای بازی پیچیدهی StarCraft II را شکست دهد. در این بازی دو رقیب به کنترل سلاح و تجهیزات میپردازند و برای تسلط بر منظرهی دیجیتالی به ساخت کلونی میپردازند. AlphaStar مجموعهای از بازیکنان را به تکامل رسانده است که با یکدیگر رقابت میکنند و از یکدیگر یاد میگیرند. بهگفتهی پژوهشگران دیپ مایند، نسخهی بهروزشدهی AlphaStar در میان ۰/۲ درصد بازیکنان برتر StarCraft II قرار گرفته است. آلفااستار اولین نوع هوش مصنوعی است که بدون هیچ محدودیتی به بالاترین لایهی رقابتهای بازیهای الکترونیکی دست پیدا میکند. مکس جادربرگ، دانشمند کامپیوتر دیپ مایند و یکی از پژوهشگران پروژه میگوید: عاملهای بازی AlphaStar پس از مدتها کار بهبود یافتهاند. با آموزش یک عامل میتوان عملکرد میانگین آن را بهبود داد، البته نیاز دارید روی عاملهای مخالف و پیدا کردن نقطهضعفها هم کار کنید.
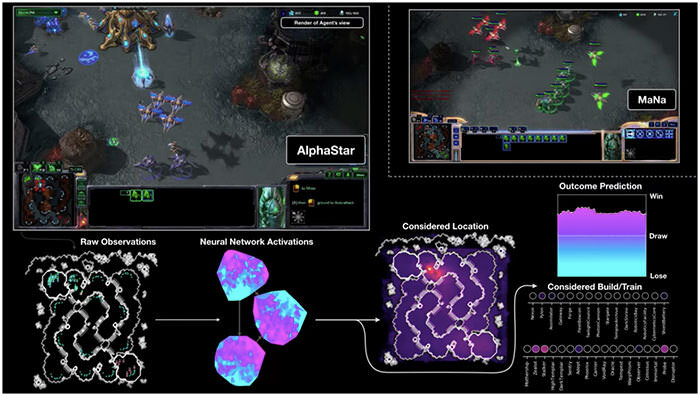
درست مانند بازی سنگ، کاغذ، قیچی، هیچ روش برتری در بازیStar Craft II وجود ندارد؛ بنابراین DeepMind هم مجموعه عاملهای خود را برای تکامل انواع روشها تشویق میکند. برای مثال وقتی آلفااستار میتواند دو بازیکن حرفهای را بیشتر از پنج بار شکست دهد، یعنی روشهای پنج عامل مختلف از مجموعهی خود را ترکیب کرده است. پنج عامل به گونهای انتخاب میشوند که تمام آنها نسبت به راهبردهای حریف آسیبپذیر نباشند. نقطهی قوت آنها هم تنوعشان است.
هوش مصنوعی تکاملیافته میتواند هوشهای دیگری را تولید کند
آلفااستار یکی از کاربردهای اصلی الگوریتمهای تکاملی را نشان میدهد: حفظ جمعیت راهحلهای مختلف. پروژهی جدید دیگری از DeepMind، کاربرد دیگری از تکامل عصبی را نشان میدهد: بهینهسازی راهحل واحد. آلفابت با همکاری پروژهی خودروی خودگردان Waymo، روی تکامل الگوریتمهایی برای شناسایی پیادهروها کار میکند. این روش عملکرد نسبتا خوبی دارد اما بهترین روش ممکن نیست. به همین دلیل پژوهشگرها برای اجتناب از بنبست، زیرمجموعههایی را تشکیل دادهاند تا اجراکنندگان قبل از رسیدن به بنبست، زمان کافی را برای توسعه داشته باشند.
محبوبیت الگوریتمهای جمعیتمحور در سالهای اخیر افزایش یافته است. بهگفتهی اریا هادسل، دانشمند پژوهشی و سرپرست رباتیک DeepMind، یکی از دلایل این محبوبیت، قدرت تطبیق این الگوریتمها با انواع محاسبات است. هادسل در ماه ژوئن سال گذشته از کلان، لمان و استنلی دعوت کرد تا در کنفرانس بینالمللی یادگیری ماشین دربارهی کارهای خود صحبت کنند. او میگوید: «معتقدم تکامل عصبی یکی از حوزههای مهم در پژوهشهای هوش مصنوعی و مکملی برای روشهای یادگیری عمیق است.»
هوش مصنوعی که قادر به تولید هوش مصنوعی است
تمام الگوریتمهای یادشده، محدودیت خلاق دارند. AlphaStar تنها میتواند راهبردهای جدیدی را برای بازی StarCraft II ارائه دهد. روش جستجوی نوآورانه در یک زمان تنها قادر به انجام یک کار است که میتواند حل هزارتو یا راه رفتن ربات باشد.
از سوی دیگر، تکامل بیولوژیکی دارای نوآوری بیانتها است. در این نوع تکامل، باکتریها، موجودات دریایی، پرندگان و انسانها نقش دارند. با تکامل راهحلها، مسئلهها هم به تکامل میرسند. زرافه در پاسخ به مسئلهی درخت به وجود آمده است. نوآوری انسان هم به همین ترتیب پیش میرود. انسان مسئلهها را برای خود خلق میکند. برای مثال از خود میپرسد: آیا میتوان انسان را به ماه فرستاد؟ و سپس برای حل مسئلهها تلاش میکند.
برای نمایش تعامل بین راهحلها و مسئلهها، استنلی، کلان و لمان و دیگر همکاران آنها در اوبر از جمله رویی وانگ در اوایل سال گذشته، الگوریتمی بهنام POET (مخفف Paired Open Ended Trailblazer) را منتشر کردند. آنها برای تست این الگوریتم، مجموعهای از رباتهای مجازی دوپا را به تکامل رساندند. از طرفی، مجموعهای از موانع را برای رباتها به تکامل رساندند که شامل تپهها، گودالها و تنهی درختها هستند. رباتها گاهی اوقات با یکدیگر تعویض میشدند و برای فتح زمینهای جدید تلاش میکردند. برای مثال یکی از رباتها، عبور از زمین مسطح را همزمان با خم شدن یاد میگرفت. سپس بهصورت تصادفی به منظرهای با تنههای درخت کوتاه میرفت و در آنجا باید راه رفتن را یاد میگرفت. به این ترتیب، پس از بازگشت به مانع اول، میتوانست سریعتر مراحل را طی کند. مسیر غیرمستقیم باعث میشود ربات مهارتهای یکی از پازلها را بهبود دهد و آن را روی پازلی دیگر اجرا کند.

جف کلان، دانشمند کامپیوتر آزمایشگاه Uber AI و دانشگاه ویومینگ، معتقد است اکتشاف پایان باز (مسئلهای که راهحلهای مختلفی برای آن وجود دارد)، سریعترین راه دستیابی به هوش مصنوعی مشابه انسان است
الگوریتم POET قادر است با ابداع چالشهای مختلف برای خود و سپس حل آنها، شکلهای جدیدی از هنر را خلق کند یا به اکتشافات جدید علمی برسد. این الگوریتم با توانایی ساخت دنیای خود، میتواند بسیار فراتر از محدودیتها عمل کند. استنلی امیدوار است بتواند الگوریتمهایی بسازد که حتی پس از یک میلیارد سال، نوآوری آنها به پایان نرسد. استنلی میگوید: تکامل منجر به تولید بینایی، فتوسنتز، هوش انسانی و در یک کلام تولید همه چیز تنها با یک الگوریتم شده است. بنابراین، برای فرآیندهای کوچک بسیار قدرتمندتر عمل خواهد کرد.
کلان معتقد است، اکتشاف پایان باز (نوعی از اکتشاف که تنها یک راهحل برای آن وجود ندارد) سریعترین روش حرکت به سمت هوش مصنوعی عمومی است. هوش مصنوعی عمومی به ماشینهایی گفته میشود که تقریبا کل تواناییهای انسان را دارند. هوش مصنوعی بیشتر متمرکز بر طراحی اجزای سازندهی ماشینهای هوشمند از جمله انواع مختلف معماریهای شبکههای عصبی و فرآیندهای یادگیری ماشین است؛ اما هنوز روش مشخصی برای ترکیب انواع هوش و رسیدن به هوش مصنوعی وجود ندارد.
از طرفی، کلان معتقد است باید بیشتر به هوش مصنوعی تولیدکنندهی هوش توجه کرد. الگوریتمها میتوانند با روشی مثل POET، به طراحی و تکامل شبکههای عصبی و محیطهایی برای یادگیری بپردازند. اکتشاف باز، میتواند از طریق مسیرهایی غیرقابل پیشبینی به هوشی در سطح انسان یا هوشی فرازمینی بینجامد. از چنین هوشی میتوان برای یادگیری بیشتر دربارهی انواع هوش هم استفاده کرد. کلان میگوید: پس از دهها سال پژوهش، هنوز هم الگوریتمها ما را شگفتزده میکنند؛ بنابراین نمیتوانیم با اطمینان بگوییم نتایج کل فرآیندها را میدانیم بهویژه که قدرت آنها روزبه روز افزایش پیدا میکند.
کنترل بیش از حد پژوهشگرها هم بیهوده است. استنلی در ابتدا سایت Picbreeder را برای مؤسسهی ملی علوم ساخته بود اما این مؤسسه با بهانهی واضح نبودن پروژه، آن را رد کرد. پروژهی استنلی به مقالهها، گفتگوها، کتابها و استارتاپ Geometric Intelligence راه پیدا کرد که بعدها اوبر آن را خرید و آزمایشگاه Uber AI را تأسیس کرد. استنلی میگوید: داستان رسیدن من به این نقطه دقیقا مشابه فرایند الگوریتم تکاملی است. الگوریتم تکاملی، نتایجی را تولید میکند که خود را به تکامل میرسانند.


